Oi pessoal, tudo bem?
Há algum tempo atrás passei por um cenário onde uma consulta Non-Sarg era executada constantemente, gerando um alto consumo de CPU, deixando o servidor topado. Meu objetivo hoje é demonstrar como transformei a consulta em SARG diminuindo drasticamente o consumo de CPU.
*Links para os scripts no final do post.
Após utilizarmos o script 1 para dar carga, iremos para o script 2, onde faremos a criação do seguinte índice na coluna principal em que faremos filtro:

É necessário estar ciente que o data type da coluna em questão é varchar e as “datas” estão gravadas no seguinte formato: 25/08/2019
Após eu ter mencionado “datas” você pode se perguntar o motivo deste dado não estar armazenado em um data type indicado para o armazenamento de datas, é … digamos que acontece… rsrs
Vamos a query:
Podemos notar que o CONVERT foi utilizado para transformar os dados de VARCHAR para DATE e buscar dentro de uma range.
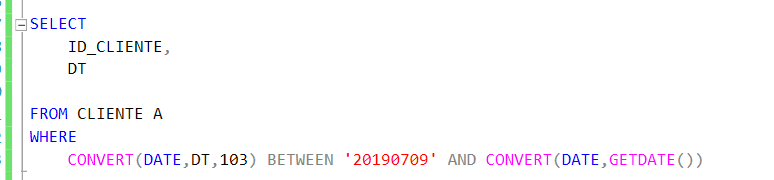
Obtemos as seguintes estatísticas ao executar:

Analisando o plano, é possível notar que o otimizador de consultas preferiu fazer um TABLE SCAN do que acessar o índice pela data que criamos.
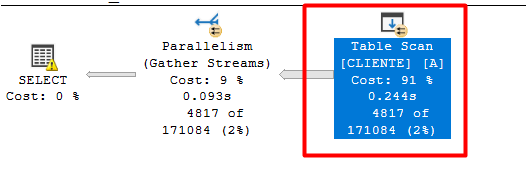
Caso você se pergunte como seria a performance se fosse utilizado aquele índice, aqui está:
Forçando o índice com o HINT:
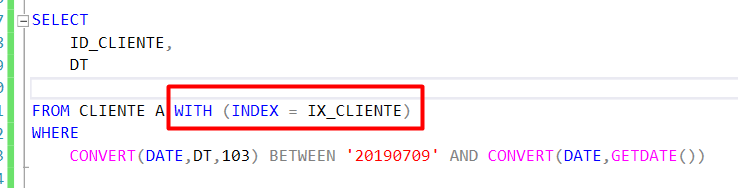
Antes/Depois: (Isto pode variar)

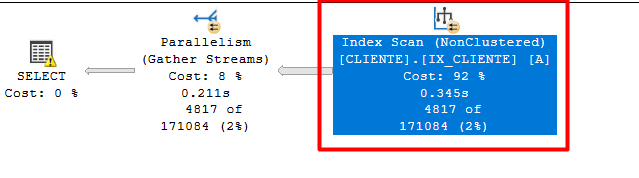
Plano com o HINT:
Sim, por ser Non-SARG, ele precisa fazer um SCAN, não utilizando a estrutura BTREE de uma forma eficiente. (SEEK)
Temos algumas soluções disponíveis para nos auxiliar neste caso, como uso de colunas computadas, porém, a solução que irei aplicar envolve somente a reescrita da query:
Solução:
Sabendo o range do filtro, posso listar todas as datas possíveis dentro do intervalo e fazer a comparação com os dados em específico, veja:
1º Criar todas as datas possíveis no range passado:
Abaixo, eu estou utilizando uma CTE RECURSIVA para gerar os dados neste range.
(Poderia gerar os dados de outras maneiras, fazendo o uso de cursores ou while, porém, a CTE Recursiva costuma ter um menor custo)
OBS: Utilizei o OPTION(MAXRECURSION 0) para que não haja limite na recursividade, pois o default é 100.
Para quem não conhece este recurso, vai uma explicação lógica rápida:
- Na primeira parte do select eu retorno a data inicial.
- Utilizo o UNION ALL (parte da sintaxe) e consulto a própria CTE que irá encontrar inicialmente o valor de @DATA_PASSADA, adicionando neste valor 1 dia.
- O WHERE faz a validação para que a recursividade continue até retornar a data atual, atendendo nosso objetivo.
- Manipulo a data gerada para o mesmo formato da tabela física que iremos consultar e gero uma tabela temporária com a saída destes dados.
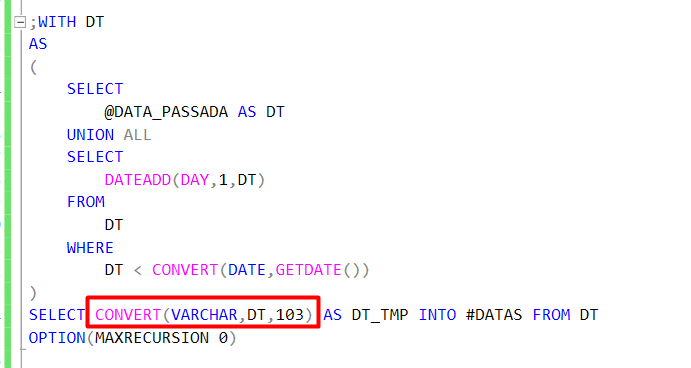
2 º Agora que temos os dados tratados, iremos aplicar um filtro na consulta:
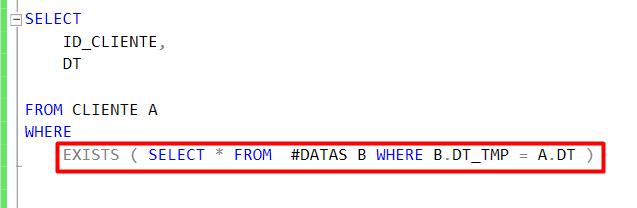
Estatísticas:
Podemos notar que houve uma excelente redução, principalmente em termos de CPU.

Plano gerado:
No plano gerado, notamos que agora ele consegue usar o índice de forma eficaz, utilizando o operador Index SEEK.
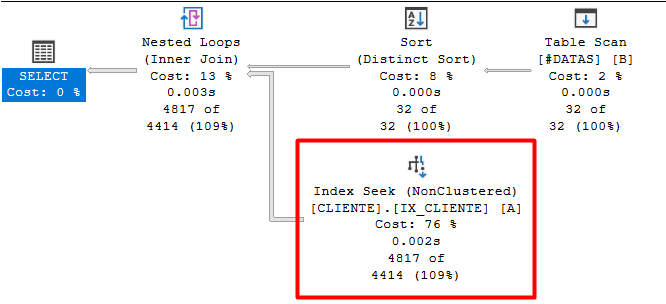
Algumas observações sobre o plano:
- Ao fazer o EXISTS, o SEEK acontece por dois motivos:
- Por conta do operador Nested Loops que obtém linha por linha da tabela temporária e procura na tabela CLIENTE e como há um índice por data, ele consegue fazer o SEEK.
- Devido a não termos mais manipulações na coluna que está sendo filtrada. (SARG)
- Notamos também um operador de SORT DISTINCT, isto acontece para que um valor que já foi consultado não seja consultado novamente, evitando um trabalho que já foi feito. Um ponto de melhoria dependendo do restante de estrutura da query:
- Criação de um índice único por data na tabela temporária para que em tempo de execução não seja feito a ordenação. (Preço pago na criação do índice)
- Dependendo de diversos fatores e principalmente da quantidade de linhas estimada na tabela Cliente e/ou na tabela temporária, é possível que seja trocado o operador de JOIN, fazendo com que não haja mais operação de SEEK, o que não quer dizer uma redução de performance.
- Considerando a possibilidade da troca de operador de JOIN, é uma boa ideia ter um índice único na tabela temporária, até mesmo para auxiliar na decisão do otimizador de consultas. Por exemplo: Decisão de escolha dos algoritmos de JOIN, onde é possível que sem o índice único, o Algoritmo Merge Join possa deixar de ser usado pois seria considerado Many-To-Many = True, levando o otimizador de consultas a considerar outro operador)
Conclusão:
De modo geral, o objetivo é mostrar o qual impactante um filtro SARG pode ser e também apresentar uma maneira diferente de reescrever a query, onde a mesma ideia pode ser aplicada em outros cenários.
Fiquem a vontade para comentar e darem sugestão de melhorias.
Um abraço e até a próxima.
Link para os scripts utilizados: https://github.com/Nusyc/CPUTopadaVsQueryNonSarg/
OBS:
- Rodar script 1 (Pode demorar alguns minutos)
- Script 2 contém os códigos descritos no post.

Márcio, é ótimo estar à procura de novas soluções. Na solução que postou, observe que é necessário que os valores das estatísticas de geração da tabela temporária sejam acrescentados aos valores de execução da consulta reescrita, para então se ter noção do ganho real.
“Sargable é tech, sargable é pop” 🙂
CurtirCurtir